Evaluations in LLMKit
Evals! Evals! Evals!
Building any LLM powered product requires you to have a deep understanding of the quality of your prompts. You need to know how they are performing and you need to be able to assess how small changes are affecting the performance.
What Are Evaluations?
Evaluations let you systematically test your prompts by running them against a set of inputs and reviewing the outputs. They’re essential for:
- Checking how your prompt performs across different scenarios.
- Comparing multiple versions of a prompt.
- Identifying weaknesses to improve.
In short, evaluations are your tool for ensuring your prompts are effective and ready for action.
Creating an Evaluation
Step 1: Navigate to Evals
From the main dashboard, head to the Evals tab. Select the prompt you want to create an eval for and click "Create new test eval".
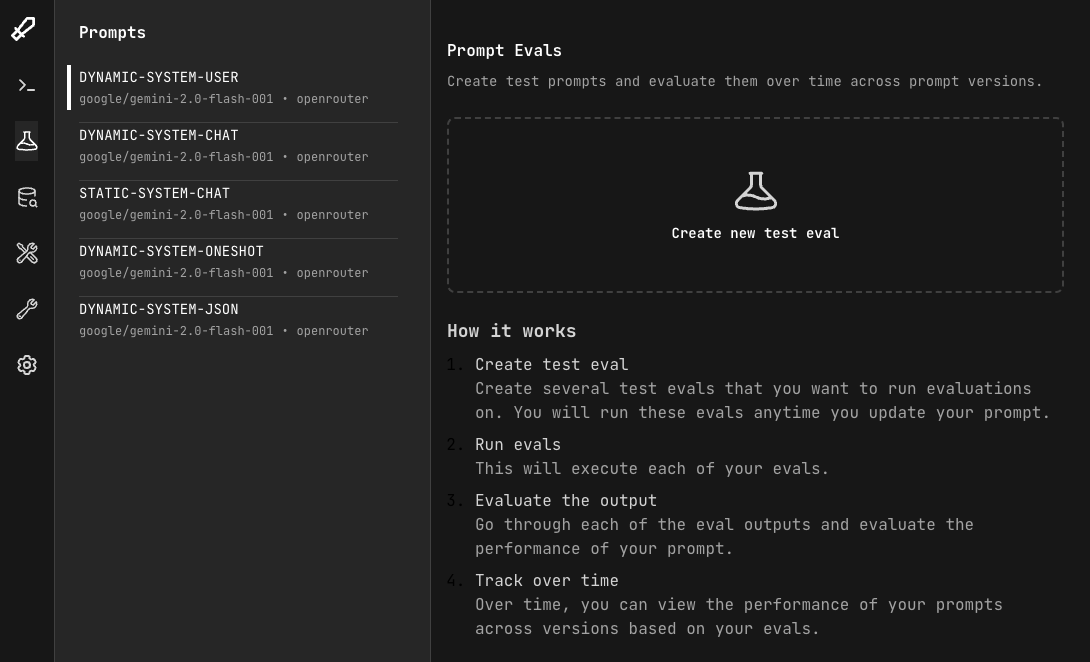
Step 2: Define template field inputs
Name your eval and populate the template fields for your prompt. Click "Add eval" when complete.
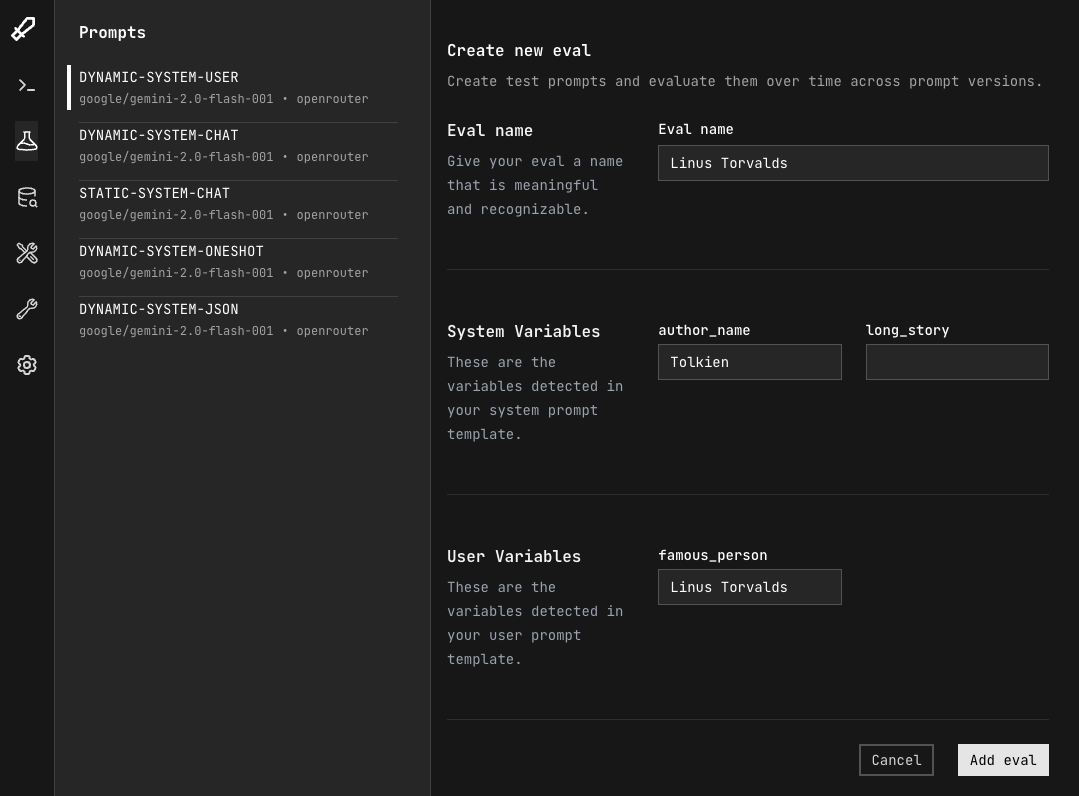
Step 3: Create more evals
Create as many evals as you want to help cover your various testing scenarios.
Running an Evaluation
Once your evals are created, it's time to run them!
Step 1: Run the evals
With the same prompt selected, select "New eval run"
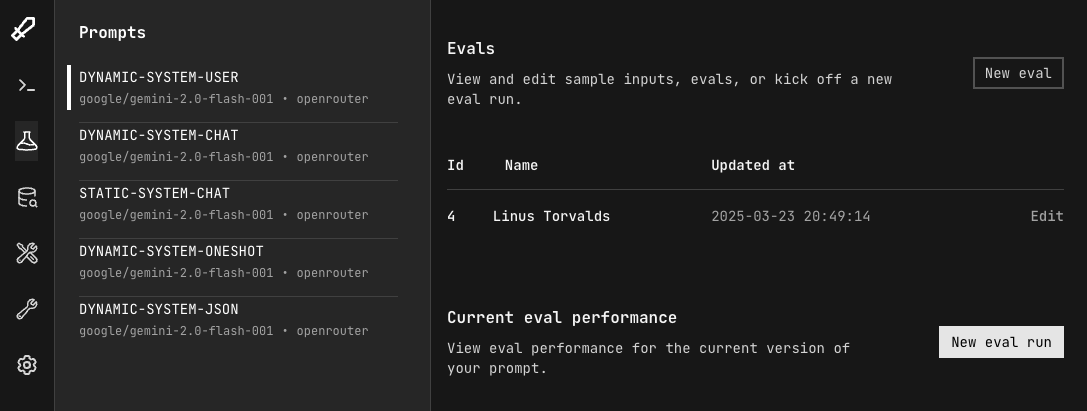
Step 2: Perform human evaluations
Once the evals are complete, you will see the inputs and outputs of your eval. Here you can select a 1-5 rating for each.
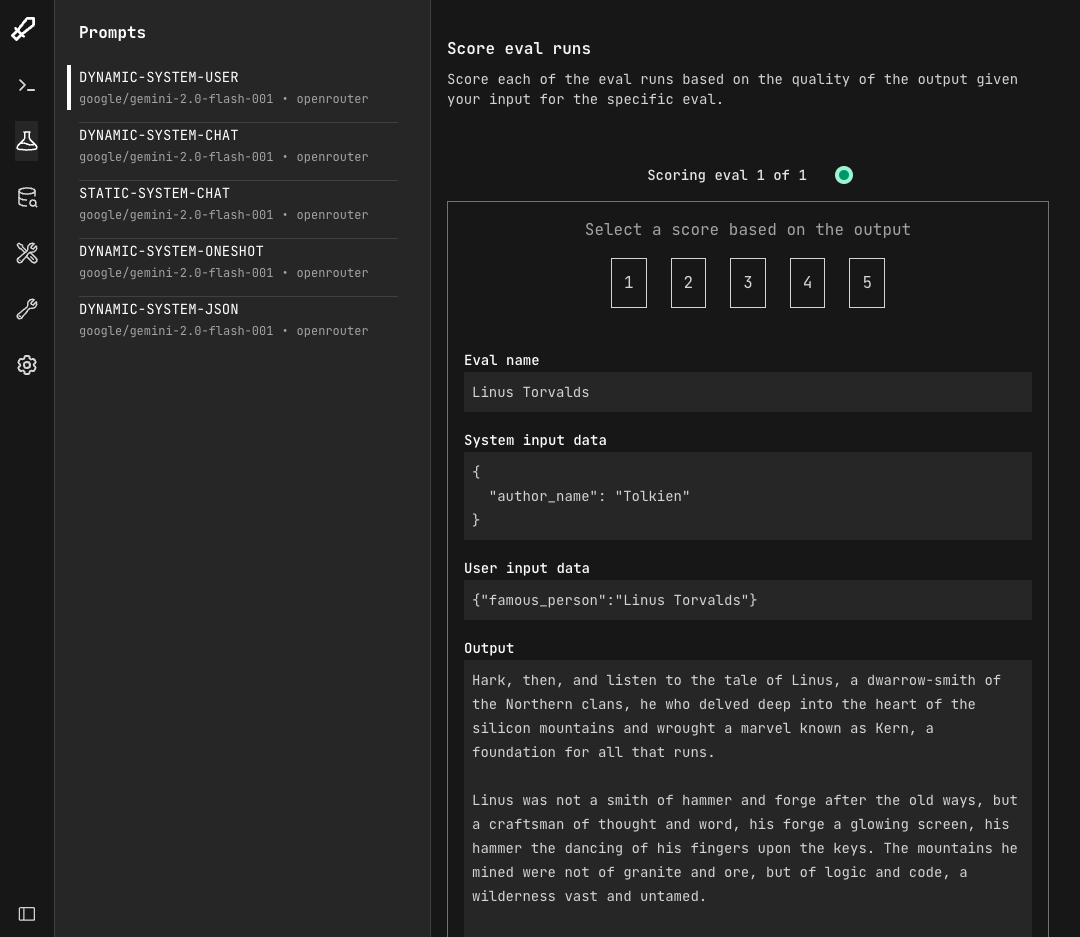
Step 3: View the results
Once you provide a rating for all the evals, you can see the results and track your prompt performance over time across versions.
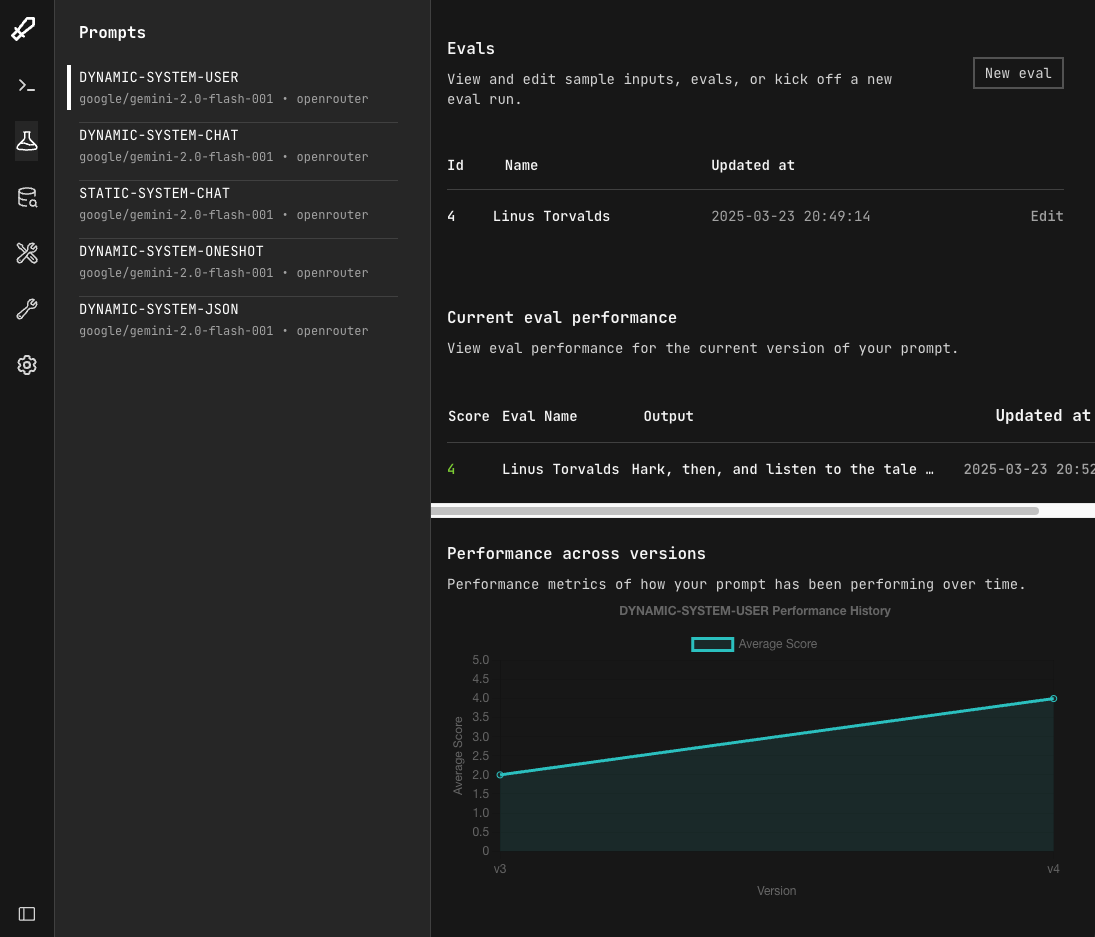
Why Evaluations Matter
Evaluations streamline the process of perfecting your prompts. They offer:
- Structured Testing: Test a range of inputs methodically.
- Performance Tracking: See how changes improve your prompt over time.
- Confidence: Validate your prompt before deploying it.